L’acronimo VinKo sta per Varietà in Contatto, un progetto di ricerca condotto in collaborazione dalle Università di Verona, Trento e Bolzano (2018-2022) che costituisce il punto di partenza di AlpiLinK. VinKo era un’infrastruttura di ricerca con lo scopo di documentare e analizzare i dialetti e le lingue minoritarie dell’Italia nord-orientale (in particolare delle regioni del Veneto e del Trentino-Alto Adige). Le varietà in contatto erano da un lato i dialetti tirolesi e le lingue minoritarie germaniche mòcheno, cimbro, saurano e sappadino, dall’altro le varietà venete, veneto-lombarde e ladine. L’infrastruttura comprendeva una piattaforma internet per la raccolta e la rappresentazione dei dati linguistici, un repository per la conservazione permanente dei dati e diverse iniziative di sensibilizzazione del pubblico, in particolare un progetto con le scuole secondarie di secondo grado del Veneto denominato VinKiamo.
L’obiettivo di VinKo era quello di permettere il confronto fra le strutture linguistiche dell’italiano e del tedesco. Ad oggi sono disponibili analisi geolinguistiche sistematiche relative alla morfologia degli articoli e dei pronomi (Kruijt 2022), all’uso dei soggetti espletivi con i verbi metereologici (Tomaselli & Bidese 2023) e all’uso dell’articolo espletivo con i nomi propri (Rabanus 2023). Ad esempio, la seguente frase può essere utilizzata nell’ambito di una ricerca sull’uso dell’articolo definito con il nome proprio (ad esempio il Gianni, la Maria invece di Gianni e Maria): In diesem Saal ist Maria die schönste/In questa stanza Maria è la più bella (S0015).
Nel dialetto tirolese di Fiè allo Sciliar (BZ) questa frase viene realizzata come: In dem Saal isch die Maria die schianschte.
Nel dialetto veneto di Grezzana in provincia di Verona si dice: In questo locale la Maria l’è la più bela.
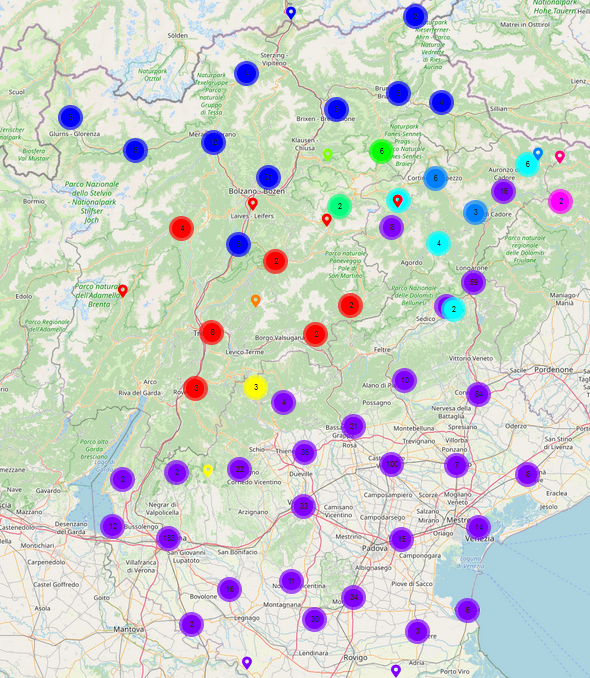
Basandosi sui dati raccolti in VinKo, Rabanus (2023) ha mostrato che nella provincia di Trento i nomi propri sono accompagnati dall’articolo espletivo nel 74% dei casi, mentre nella regione Veneto solo nel 22% dei casi. Questo dimostra che, per quanto riguarda l’utilizzo dell’articolo espletivo, il confine tra le province di Trento e Verona (in quanto parte del Veneto) è più rilevante di quello tra le province di Trento e Bolzano (dove l’articolo espletivo viene usato in circa il 90% dei casi), sebbene quest’ultimo corrisponda al confine linguistico italo-tedesco. Una descrizione più dettagliata dei risultati di questo studio si trova nella sezione “Risultati“, cioè qui.