The acronym VinKo stands for Varieties in Contact, the research project from the Universities of Verona, Trento and Bolzano-Bozen (2018-2022), which laid the foundation for the AlpiLink project. VinKo featured a research infrastructure with the purpose of documenting and analyzing dialects and minority languages in northeastern Italy (regions of Trentino-South Tyrol and Veneto). The varieties in contact were the Tyrolean dialects and the German minority languages Mòcheno, Cimbrian, Saurano and Sappadino on the one hand and the Venetan or Veneto-Lombard and Ladin varieties on the other. The infrastructure included an Internet platform for the collection and representation of linguistic data, a repository for the permanent preservation of data, and various public outreach initiatives, e.g. a project with Venetan secondary schools called VinKiamo.
The goal of VinKo was to enable comparisons of German and Italian language structures; systematic geolinguistic analyses of variation are available so far on the morphology of articles and pronouns (Kruijt 2022), on subject expletives in weather verbs (Tomaselli & Bidese 2023), and on the expletive article in personal names (Rabanus 2023). For example, for research into the use of a definite article with a personal name (e.g. the John, the Mary, instead of John and Mary), the following sentence may be used: In diesem Saal ist Maria die schönste/In questa stanza Maria è la più bella (S0015).
The Tyrolean dialect of Völs am Schlern translates this sentence as In dem Saal isch die Maria die schianschte.
In the Venetan dialect of Grezzana in the province of Verona this is translated as: In questo locale la Maria l’è la più bela.
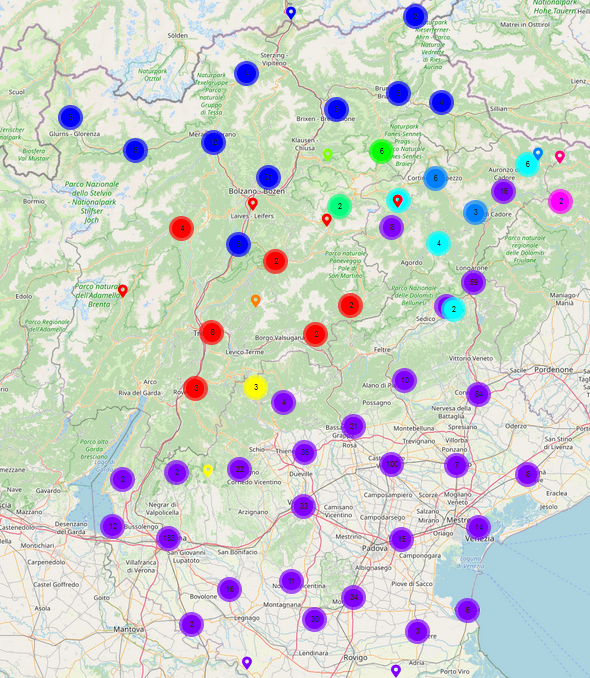
Rabanus (2023) can show with the VinKo data that in the province of Trento, personal names have expletive articles in about 74% of the cases, in the region of Veneto only in about 22% of the cases. Thus, interestingly, the border between the provinces of Trento and Verona is more relevant for the use of the expletive article than the border between the provinces of Trento and Bolzano (expletive articles in about 90% of the cases), which corresponds to the German-Italian language border. A more detailed description of the results of this investigation can be found in the “Results” section, here.